bias_variance_decomp: Bias-variance decomposition for classification and regression losses
Bias variance decomposition of machine learning algorithms for various loss functions.
from mlxtend.evaluate import bias_variance_decomp
Overview
Often, researchers use the terms bias and variance or "bias-variance tradeoff" to describe the performance of a model -- i.e., you may stumble upon talks, books, or articles where people say that a model has a high variance or high bias. So, what does that mean? In general, we might say that "high variance" is proportional to overfitting, and "high bias" is proportional to underfitting.
Anyways, why are we attempting to do this bias-variance decomposition in the first place? The decomposition of the loss into bias and variance helps us understand learning algorithms, as these concepts are correlated to underfitting and overfitting.
To use the more formal terms for bias and variance, assume we have a point estimator of some parameter or function . Then, the bias is commonly defined as the difference between the expected value of the estimator and the parameter that we want to estimate:
If the bias is larger than zero, we also say that the estimator is positively biased, if the bias is smaller than zero, the estimator is negatively biased, and if the bias is exactly zero, the estimator is unbiased. Similarly, we define the variance as the difference between the expected value of the squared estimator minus the squared expectation of the estimator:
Note that in the context of this lecture, it will be more convenient to write the variance in its alternative form:
To illustrate the concept further in context of machine learning ...
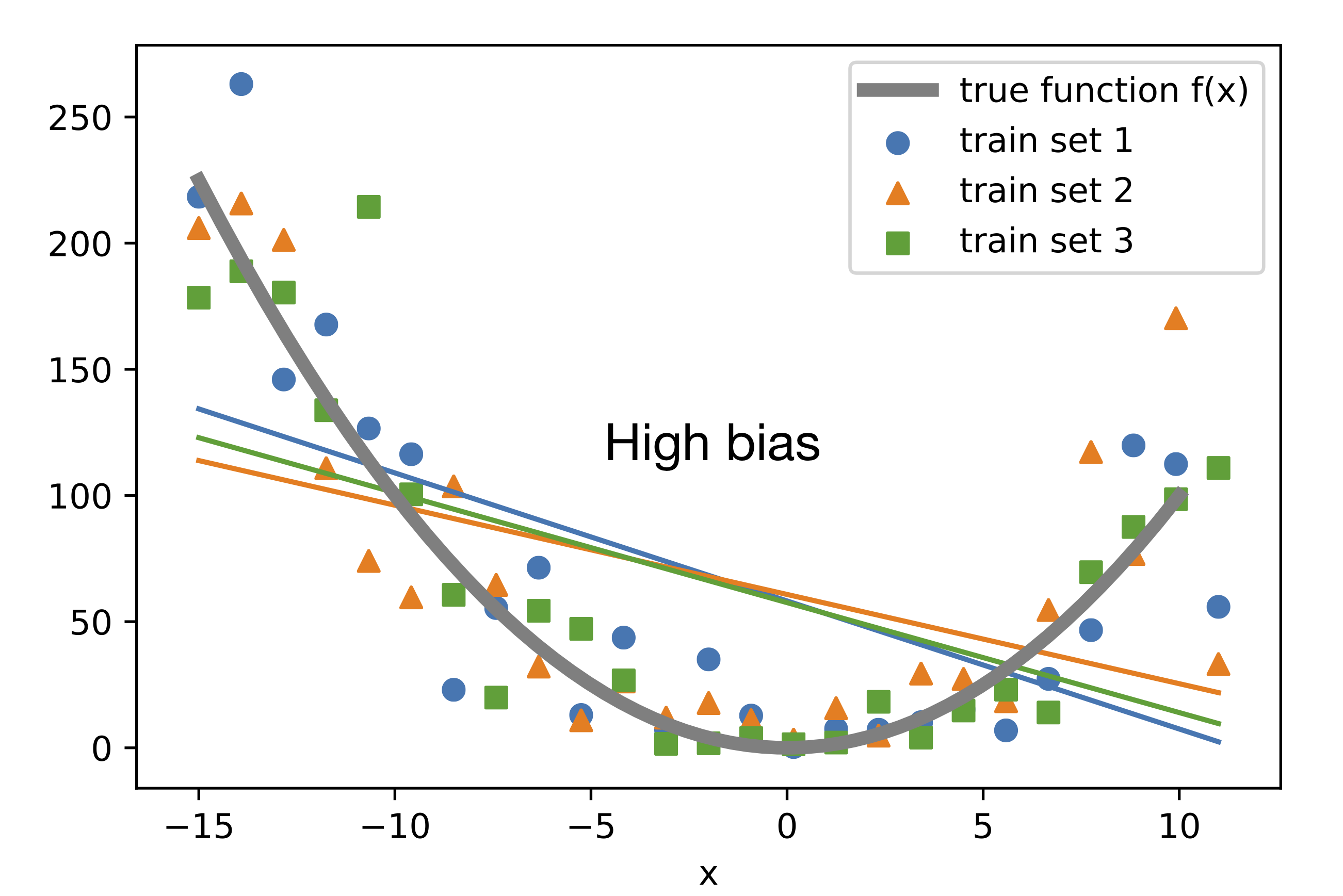
Suppose there is an unknown target function or "true function" to which we do want to approximate. Now, suppose we have different training sets drawn from an unknown distribution defined as "true function + noise." The following plot shows different linear regression models, each fit to a different training set. None of these hypotheses approximate the true function well, except at two points (around x=-10 and x=6). Here, we can say that the bias is large because the difference between the true value and the predicted value, on average (here, average means "expectation of the training sets" not "expectation over examples in the training set"), is large:
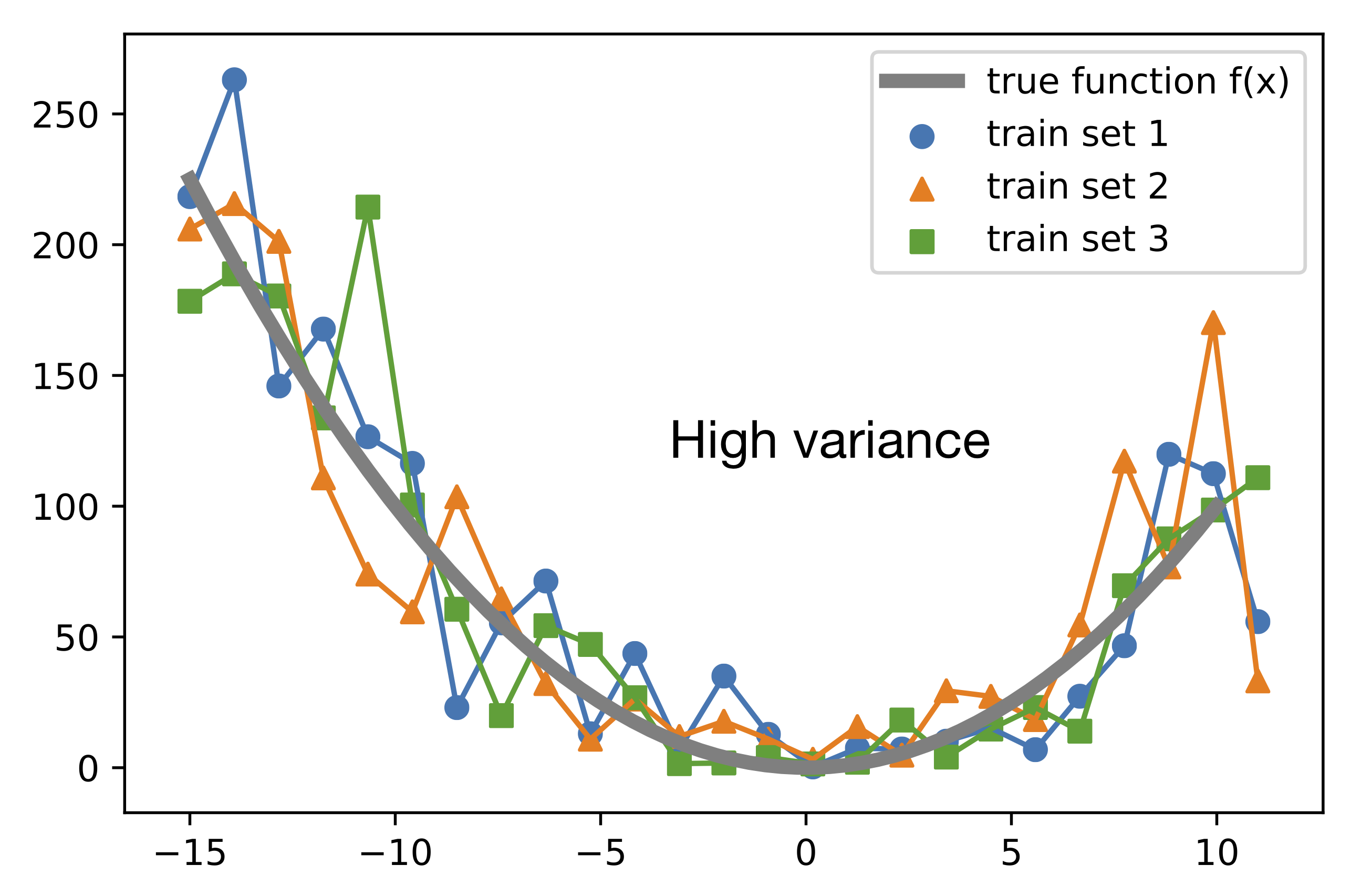
The next plot shows different unpruned decision tree models, each fit to a different training set. Note that these hypotheses fit the training data very closely. However, if we would consider the expectation over training sets, the average hypothesis would fit the true function perfectly (given that the noise is unbiased and has an expected value of 0). As we can see, the variance is very large, since on average, a prediction differs a lot from the expectation value of the prediction:
Bias-Variance Decomposition of the Squared Loss
We can decompose a loss function such as the squared loss into three terms, a variance, bias, and a noise term (and the same is true for the decomposition of the 0-1 loss later). However, for simplicity, we will ignore the noise term.
Before we introduce the bias-variance decomposition of the 0-1 loss for classification, let us start with the decomposition of the squared loss as an easy warm-up exercise to get familiar with the overall concept.
The previous section already listed the common formal definitions of bias and variance, however, let us define them again for convenience:
Recall that in the context of these machine learning lecture (notes), we defined
- the true or target function as ,
- the predicted target value as ,
- and the squared loss as . (I use here because it will be easier to tell it apart from the , which we use for the expectation in this lecture.)
Note that unless noted otherwise, the expectation is over training sets!
To get started with the squared error loss decomposition into bias and variance, let use do some algebraic manipulation, i.e., adding and subtracting the expected value of and then expanding the expression using the quadratic formula :
Next, we just use the expectation on both sides, and we are already done:
You may wonder what happened to the "" term () when we used the expectation. It turns that it evaluates to zero and hence vanishes from the equation, which can be shown as follows:
So, this is the canonical decomposition of the squared error loss into bias and variance. The next section will discuss some approaches that have been made to decompose the 0-1 loss that we commonly use for classification accuracy or error.
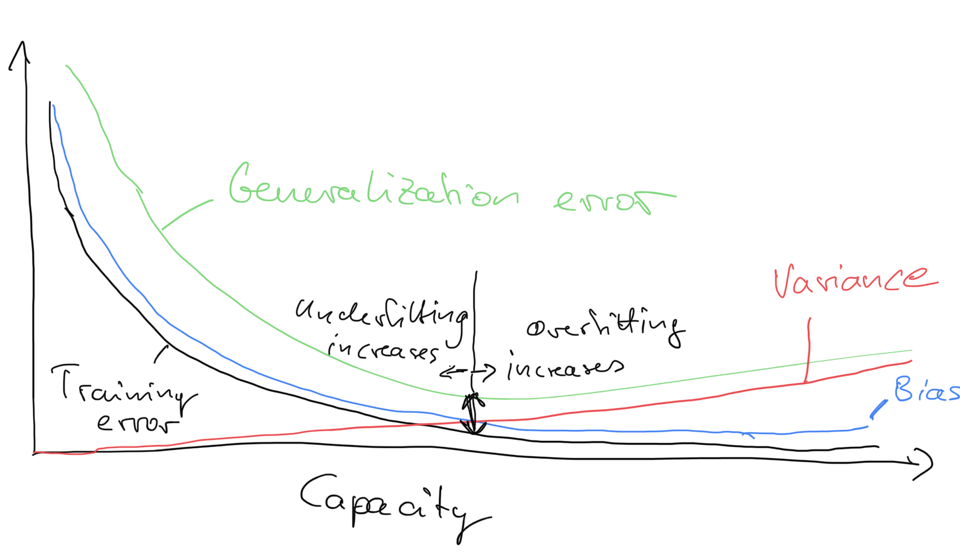
The following figure is a sketch of variance and bias in relation to the training error and generalization error -- how high variance related to overfitting, and how large bias relates to underfitting:
Bias-Variance Decomposition of the 0-1 Loss
Note that decomposing the 0-1 loss into bias and variance components is not as straight-forward as for the squared error loss. To quote Pedro Domingos, a well-known machine learning researcher and professor at University of Washington:
"several authors have proposed bias-variance decompositions related to zero-one loss (Kong & Dietterich, 1995; Breiman, 1996b; Kohavi & Wolpert, 1996; Tibshirani, 1996; Friedman, 1997). However, each of these decompositions has significant shortcomings.". [1]
In fact, the paper this quote was taken from may offer the most intuitive and general formulation at this point. However, we will first, for simplicity, go over Kong & Dietterich formulation [2] of the 0-1 loss decomposition, which is the same as Domingos's but excluding the noise term (for simplicity).
The table below summarizes the relevant terms we used for the squared loss in relation to the 0-1 loss. Recall that the 0-1 loss, , is 0 if a class label is predicted correctly, and one otherwise. The main prediction for the squared error loss is simply the average over the predictions (the expectation is over training sets), for the 0-1 loss Kong & Dietterich and Domingos defined it as the mode. I.e., if a model predicts the label one more than 50% of the time (considering all possible training sets), then the main prediction is 1, and 0 otherwise.
| - | Squared Loss | 0-1 Loss |
|---|---|---|
| Single loss | ||
| Expected loss | ||
| Main prediction | mean (average) | mode |
| Bias | ||
| Variance |
Hence, as result from using the mode to define the main prediction of the 0-1 loss, the bias is 1 if the main prediction does not agree with the true label , and 0 otherwise:
The variance of the 0-1 loss is defined as the probability that the predicted label does not match the main prediction:
Next, let us take a look at what happens to the loss if the bias is 0. Given the general definition of the loss, loss = bias + variance, if the bias is 0, then we define the loss as the variance:
In other words, if a model has zero bias, it's loss is entirely defined by the variance, which is intuitive if we think of variance in the context of being proportional overfitting.
The more surprising scenario is if the bias is equal to 1. If the bias is equal to 1, as explained by Pedro Domingos, the increasing the variance can decrease the loss, which is an interesting observation. This can be seen by first rewriting the 0-1 loss function as
(Note that we have not done anything new, yet.) Now, if we look at the previous equation of the bias, if the bias is 1, we have . If is not equal to the main prediction, but is also is equal to , then must be equal to the main prediction. Using the "inverse" ("1 minus"), we can then write the loss as
Since the bias is 1, the loss is hence defined as "loss = bias - variance" if the bias is 1 (or "loss = 1 - variance"). This might be quite unintuitive at first, but the explanations Kong, Dietterich, and Domingos offer was that if a model has a very high bias such that it main prediction is always wrong, increasing the variance can be beneficial, since increasing the variance would push the decision boundary, which might lead to some correct predictions just by chance then. In other words, for scenarios with high bias, increasing the variance can improve (decrease) the loss!
References
- [1] Domingos, Pedro. "A unified bias-variance decomposition." Proceedings of 17th International Conference on Machine Learning. 2000.
- [2] Dietterich, Thomas G., and Eun Bae Kong. Machine learning bias, statistical bias, and statistical variance of decision tree algorithms. Technical report, Department of Computer Science, Oregon State University, 1995.
Example 1 -- Bias Variance Decomposition of a Decision Tree Classifier
from mlxtend.evaluate import bias_variance_decomp
from sklearn.tree import DecisionTreeClassifier
from mlxtend.data import iris_data
from sklearn.model_selection import train_test_split
X, y = iris_data()
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
random_state=123,
shuffle=True,
stratify=y)
tree = DecisionTreeClassifier(random_state=123)
avg_expected_loss, avg_bias, avg_var = bias_variance_decomp(
tree, X_train, y_train, X_test, y_test,
loss='0-1_loss',
random_seed=123)
print('Average expected loss: %.3f' % avg_expected_loss)
print('Average bias: %.3f' % avg_bias)
print('Average variance: %.3f' % avg_var)
Average expected loss: 0.062
Average bias: 0.022
Average variance: 0.040
For comparison, the bias-variance decomposition of a bagging classifier, which should intuitively have a lower variance compared than a single decision tree:
from sklearn.ensemble import BaggingClassifier
tree = DecisionTreeClassifier(random_state=123)
bag = BaggingClassifier(base_estimator=tree,
n_estimators=100,
random_state=123)
avg_expected_loss, avg_bias, avg_var = bias_variance_decomp(
bag, X_train, y_train, X_test, y_test,
loss='0-1_loss',
random_seed=123)
print('Average expected loss: %.3f' % avg_expected_loss)
print('Average bias: %.3f' % avg_bias)
print('Average variance: %.3f' % avg_var)
Average expected loss: 0.048
Average bias: 0.022
Average variance: 0.026
Example 2 -- Bias Variance Decomposition of a Decision Tree Regressor
from mlxtend.evaluate import bias_variance_decomp
from sklearn.tree import DecisionTreeRegressor
from mlxtend.data import boston_housing_data
from sklearn.model_selection import train_test_split
X, y = boston_housing_data()
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
random_state=123,
shuffle=True)
tree = DecisionTreeRegressor(random_state=123)
avg_expected_loss, avg_bias, avg_var = bias_variance_decomp(
tree, X_train, y_train, X_test, y_test,
loss='mse',
random_seed=123)
print('Average expected loss: %.3f' % avg_expected_loss)
print('Average bias: %.3f' % avg_bias)
print('Average variance: %.3f' % avg_var)
Average expected loss: 31.536
Average bias: 14.096
Average variance: 17.440
For comparison, the bias-variance decomposition of a bagging regressor is shown below, which should intuitively have a lower variance than a single decision tree:
from sklearn.ensemble import BaggingRegressor
tree = DecisionTreeRegressor(random_state=123)
bag = BaggingRegressor(base_estimator=tree,
n_estimators=100,
random_state=123)
avg_expected_loss, avg_bias, avg_var = bias_variance_decomp(
bag, X_train, y_train, X_test, y_test,
loss='mse',
random_seed=123)
print('Average expected loss: %.3f' % avg_expected_loss)
print('Average bias: %.3f' % avg_bias)
print('Average variance: %.3f' % avg_var)
Average expected loss: 18.620
Average bias: 15.461
Average variance: 3.159
Example 3 -- TensorFlow/Keras Support
Since mlxtend v0.18.0, the bias_variance_decomp now supports Keras models. Note that the original model is reset in each round (before refitting it to the bootstrap samples).
from mlxtend.evaluate import bias_variance_decomp
from mlxtend.data import boston_housing_data
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import tensorflow as tf
import numpy as np
np.random.seed(1)
tf.random.set_seed(1)
X, y = boston_housing_data()
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
random_state=123,
shuffle=True)
model = tf.keras.Sequential([
tf.keras.layers.Dense(32, activation=tf.nn.relu),
tf.keras.layers.Dense(1)
])
optimizer = tf.keras.optimizers.Adam()
model.compile(loss='mean_squared_error', optimizer=optimizer)
model.fit(X_train, y_train, epochs=100, verbose=0)
mean_squared_error(model.predict(X_test), y_test)
32.69300595184836
Note that it is highly recommended to use the same number of training epochs that you would use on the original training set to ensure convergence:
np.random.seed(1)
tf.random.set_seed(1)
avg_expected_loss, avg_bias, avg_var = bias_variance_decomp(
model, X_train, y_train, X_test, y_test,
loss='mse',
num_rounds=100,
random_seed=123,
epochs=200, # fit_param
verbose=0) # fit_param
print('Average expected loss: %.3f' % avg_expected_loss)
print('Average bias: %.3f' % avg_bias)
print('Average variance: %.3f' % avg_var)
Average expected loss: 32.740
Average bias: 27.474
Average variance: 5.265
API
bias_variance_decomp(estimator, X_train, y_train, X_test, y_test, loss='0-1_loss', num_rounds=200, random_seed=None, fit_params)
estimator : object
A classifier or regressor object or class implementing both a
fit and predict method similar to the scikit-learn API.
-
X_train: array-like, shape=(num_examples, num_features)A training dataset for drawing the bootstrap samples to carry out the bias-variance decomposition.
-
y_train: array-like, shape=(num_examples)Targets (class labels, continuous values in case of regression) associated with the
X_trainexamples. -
X_test: array-like, shape=(num_examples, num_features)The test dataset for computing the average loss, bias, and variance.
-
y_test: array-like, shape=(num_examples)Targets (class labels, continuous values in case of regression) associated with the
X_testexamples. -
loss: str (default='0-1_loss')Loss function for performing the bias-variance decomposition. Currently allowed values are '0-1_loss' and 'mse'.
-
num_rounds: int (default=200)Number of bootstrap rounds (sampling from the training set) for performing the bias-variance decomposition. Each bootstrap sample has the same size as the original training set.
-
random_seed: int (default=None)Random seed for the bootstrap sampling used for the bias-variance decomposition.
-
fit_params: additional parametersAdditional parameters to be passed to the .fit() function of the estimator when it is fit to the bootstrap samples.
Returns
-
avg_expected_loss, avg_bias, avg_var: returns the average expectedaverage bias, and average bias (all floats), where the average is computed over the data points in the test set.
Examples
For usage examples, please see https://rasbt.github.io/mlxtend/user_guide/evaluate/bias_variance_decomp/