Perceptron: A simple binary classifier
Implementation of a Perceptron learning algorithm for classification.
from mlxtend.classifier import Perceptron
Overview
The idea behind this "thresholded" perceptron was to mimic how a single neuron in the brain works: It either "fires" or not. A perceptron receives multiple input signals, and if the sum of the input signals exceed a certain threshold it either returns a signal or remains "silent" otherwise. What made this a "machine learning" algorithm was Frank Rosenblatt's idea of the perceptron learning rule: The perceptron algorithm is about learning the weights for the input signals in order to draw linear decision boundary that allows us to discriminate between the two linearly separable classes +1 and -1.
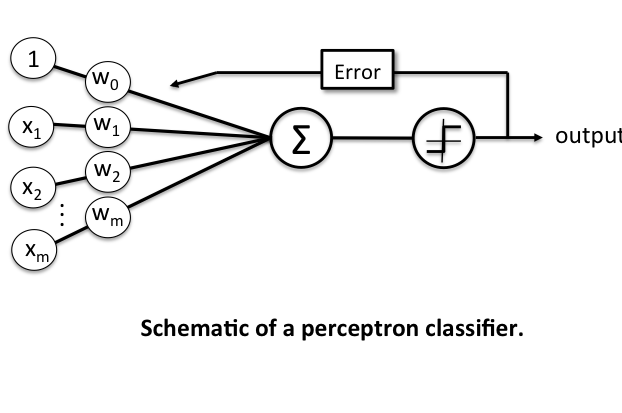
Basic Notation
Before we dive deeper into the algorithm(s) for learning the weights of the perceptron classifier, let us take a brief look at the basic notation. In the following sections, we will label the positive and negative class in our binary classification setting as "1" and "-1", respectively. Next, we define an activation function that takes a linear combination of the input values and weights as input (), and if is greater than a defined threshold we predict 1 and -1 otherwise; in this case, this activation function is a simple "unit step function," which is sometimes also called "Heaviside step function."
$$ g(z) =}\\ -1 & \text{otherwise}. \end{cases} $$
where
is the feature vector, and is an -dimensional sample from the training dataset:
In order to simplify the notation, we bring to the left side of the equation and define
so that
$$ g({z}) =}\\ -1 & \text{otherwise}. \end{cases} $$
and
Perceptron Rule
Rosenblatt's initial perceptron rule is fairly simple and can be summarized by the following steps:
- Initialize the weights to 0 or small random numbers.
- For each training sample :
- Calculate the output value.
- Update the weights.
The output value is the class label predicted by the unit step function that we defined earlier (output ) and the weight update can be written more formally as .
The value for updating the weights at each increment is calculated by the learning rule
where is the learning rate (a constant between 0.0 and 1.0), "target" is the true class label, and the "output" is the predicted class label.
aIt is important to note that all weights in the weight vector are being updated simultaneously. Concretely, for a 2-dimensional dataset, we would write the update as:
Before we implement the perceptron rule in Python, let us make a simple thought experiment to illustrate how beautifully simple this learning rule really is. In the two scenarios where the perceptron predicts the class label correctly, the weights remain unchanged:
However, in case of a wrong prediction, the weights are being "pushed" towards the direction of the positive or negative target class, respectively:
It is important to note that the convergence of the perceptron is only guaranteed if the two classes are linearly separable. If the two classes can't be separated by a linear decision boundary, we can set a maximum number of passes over the training dataset ("epochs") and/or a threshold for the number of tolerated misclassifications.
References
- F. Rosenblatt. The perceptron, a perceiving and recognizing automaton Project Para. Cornell Aeronautical Laboratory, 1957.
Example 1 - Classification of Iris Flowers
from mlxtend.data import iris_data
from mlxtend.plotting import plot_decision_regions
from mlxtend.classifier import Perceptron
import matplotlib.pyplot as plt
# Loading Data
X, y = iris_data()
X = X[:, [0, 3]] # sepal length and petal width
X = X[0:100] # class 0 and class 1
y = y[0:100] # class 0 and class 1
# standardize
X[:,0] = (X[:,0] - X[:,0].mean()) / X[:,0].std()
X[:,1] = (X[:,1] - X[:,1].mean()) / X[:,1].std()
# Rosenblatt Perceptron
ppn = Perceptron(epochs=5,
eta=0.05,
random_seed=0,
print_progress=3)
ppn.fit(X, y)
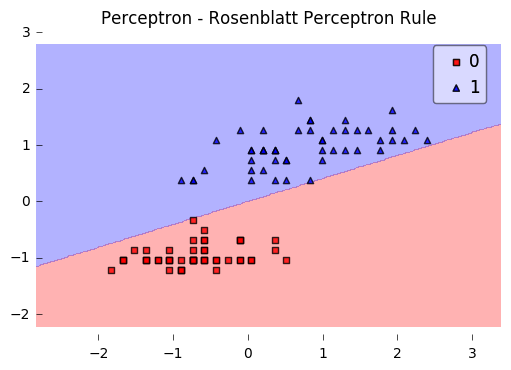
plot_decision_regions(X, y, clf=ppn)
plt.title('Perceptron - Rosenblatt Perceptron Rule')
plt.show()
print('Bias & Weights: %s' % ppn.w_)
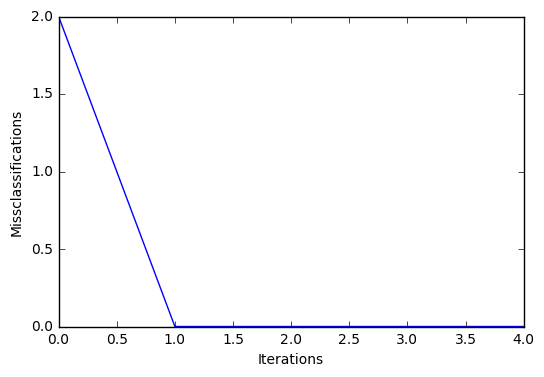
plt.plot(range(len(ppn.cost_)), ppn.cost_)
plt.xlabel('Iterations')
plt.ylabel('Missclassifications')
plt.show()
Iteration: 5/5 | Elapsed: 00:00:00 | ETA: 00:00:00
Bias & Weights: [[-0.04500809]
[ 0.11048855]]
API
Perceptron(eta=0.1, epochs=50, random_seed=None, print_progress=0)
Perceptron classifier.
Note that this implementation of the Perceptron expects binary class labels in {0, 1}.
Parameters
-
eta: float (default: 0.1)Learning rate (between 0.0 and 1.0)
-
epochs: int (default: 50)Number of passes over the training dataset. Prior to each epoch, the dataset is shuffled to prevent cycles.
-
random_seed: intRandom state for initializing random weights and shuffling.
-
print_progress: int (default: 0)Prints progress in fitting to stderr. 0: No output 1: Epochs elapsed and cost 2: 1 plus time elapsed 3: 2 plus estimated time until completion
Attributes
-
w_: 2d-array, shape={n_features, 1}Model weights after fitting.
-
b_: 1d-array, shape={1,}Bias unit after fitting.
-
cost_: listNumber of misclassifications in every epoch.
Examples
For usage examples, please see https://rasbt.github.io/mlxtend/user_guide/classifier/Perceptron/
Methods
fit(X, y, init_params=True)
Learn model from training data.
Parameters
-
X: {array-like, sparse matrix}, shape = [n_samples, n_features]Training vectors, where n_samples is the number of samples and n_features is the number of features.
-
y: array-like, shape = [n_samples]Target values.
-
init_params: bool (default: True)Re-initializes model parameters prior to fitting. Set False to continue training with weights from a previous model fitting.
Returns
self: object
predict(X)
Predict targets from X.
Parameters
-
X: {array-like, sparse matrix}, shape = [n_samples, n_features]Training vectors, where n_samples is the number of samples and n_features is the number of features.
Returns
-
target_values: array-like, shape = [n_samples]Predicted target values.
score(X, y)
Compute the prediction accuracy
Parameters
-
X: {array-like, sparse matrix}, shape = [n_samples, n_features]Training vectors, where n_samples is the number of samples and n_features is the number of features.
-
y: array-like, shape = [n_samples]Target values (true class labels).
Returns
-
acc: floatThe prediction accuracy as a float between 0.0 and 1.0 (perfect score).
ython