three_blobs_data: The synthetic blobs for classification
A function that loads the three_blobs dataset into NumPy arrays.
from mlxtend.data import three_blobs_data
Overview
A random dataset of 3 2D blobs for clustering.
- Number of samples : 150
- Suggested labels {0, 1, 2}, distribution: [50, 50, 50]
References
Example 1 - Dataset overview
from mlxtend.data import three_blobs_data
X, y = three_blobs_data()
print('Dimensions: %s x %s' % (X.shape[0], X.shape[1]))
print('1st row', X[0])
Dimensions: 150 x 2
1st row [ 2.60509732 1.22529553]
import numpy as np
print('Suggested cluster labels')
print(np.unique(y))
print('Label distribution: %s' % np.bincount(y))
Suggested cluster labels
[0 1 2]
Label distribution: [50 50 50]
import matplotlib.pyplot as plt
plt.scatter(X[:,0], X[:,1],
c='white',
marker='o',
s=50)
plt.grid()
plt.show()
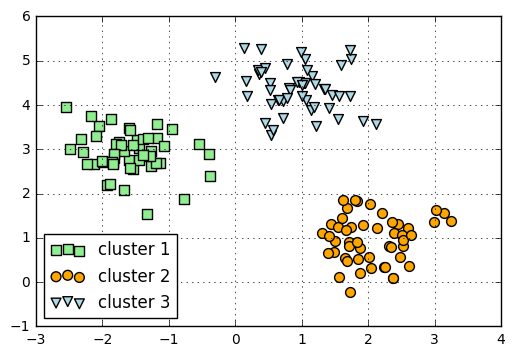
plt.scatter(X[y == 0, 0],
X[y == 0, 1],
s=50,
c='lightgreen',
marker='s',
label='cluster 1')
plt.scatter(X[y == 1,0],
X[y == 1,1],
s=50,
c='orange',
marker='o',
label='cluster 2')
plt.scatter(X[y == 2,0],
X[y == 2,1],
s=50,
c='lightblue',
marker='v',
label='cluster 3')
plt.legend(loc='lower left')
plt.grid()
plt.show()
API
three_blobs_data()
A random dataset of 3 2D blobs for clustering.
-
Number of samples: 150 -
Suggested labels: {0, 1, 2}, distribution: [50, 50, 50]
Returns
-
X, y: [n_samples, n_features], [n_cluster_labels]X is the feature matrix with 159 samples as rows and 2 feature columns. y is a 1-dimensional array of the 3 suggested cluster labels 0, 1, 2
Examples
For usage examples, please see https://rasbt.github.io/mlxtend/user_guide/data/three_blobs_data